特朗普贸易战被指注定失败:中方将捍卫国家利益
百度 融资困难+降低成本在摘牌企业中,出现频率较多的摘牌理由,则是出于业务发展及降低成本需求,申请终止挂牌。关注百度智能云最新动态,了解产业智能化最新成果
AI推理加速原理解析与工程实践分享
2025-08-03 17:06:18

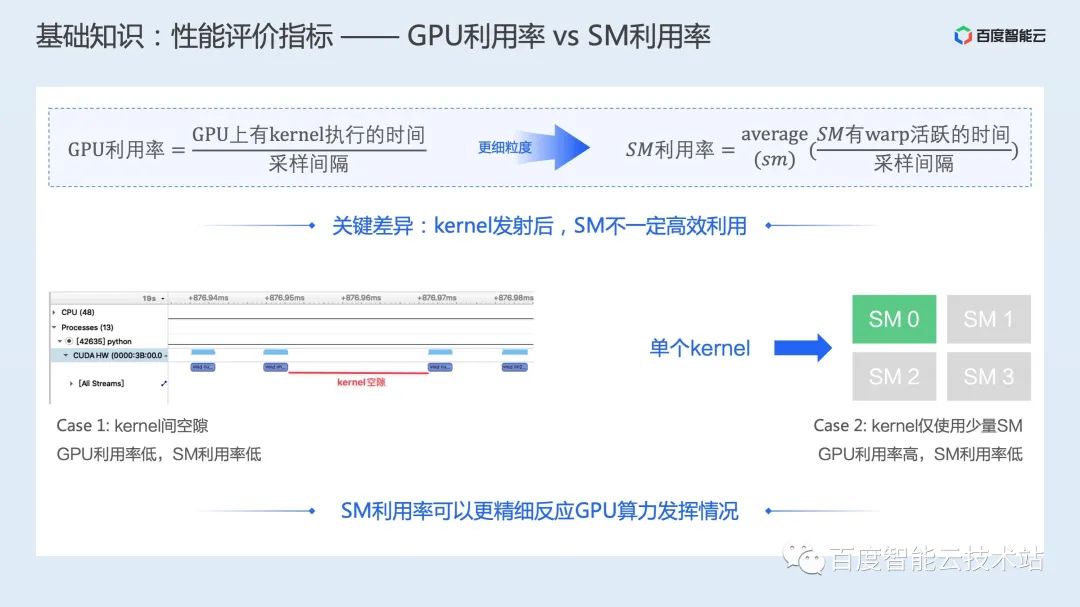
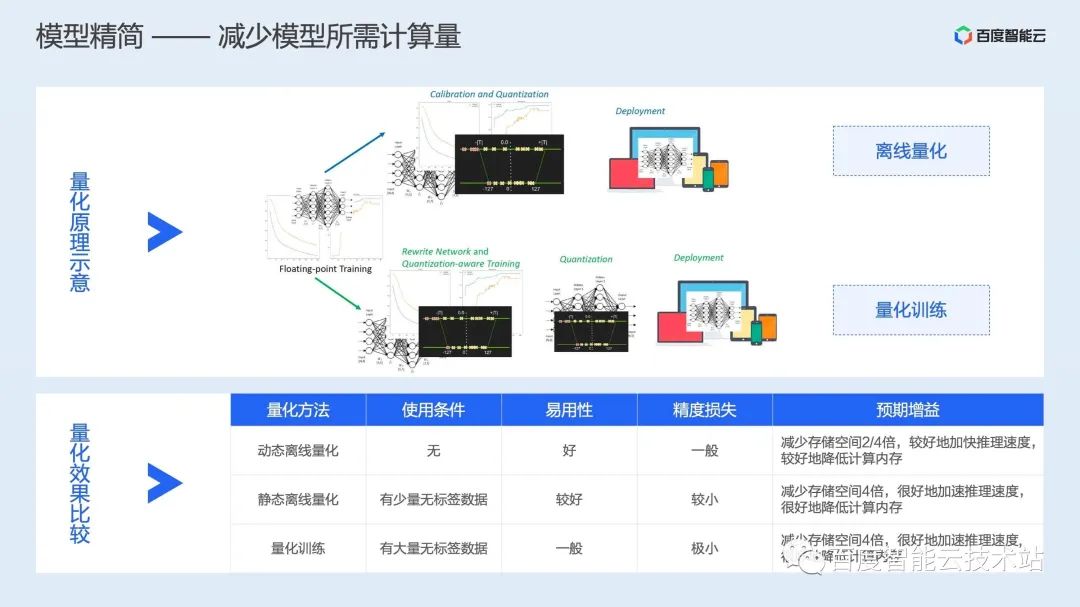
离线量化是指在模型训练完成后,离线的对计算算子进行量化,这种方案通常易用性较好,对算法开发人员几乎透明,但对模型精度会有一定损失; 量化训练则是在模型训练过程中就显示插入量化相关的操作,这样通常会有更好的精度,但需要算法开发同学准备相关数据。

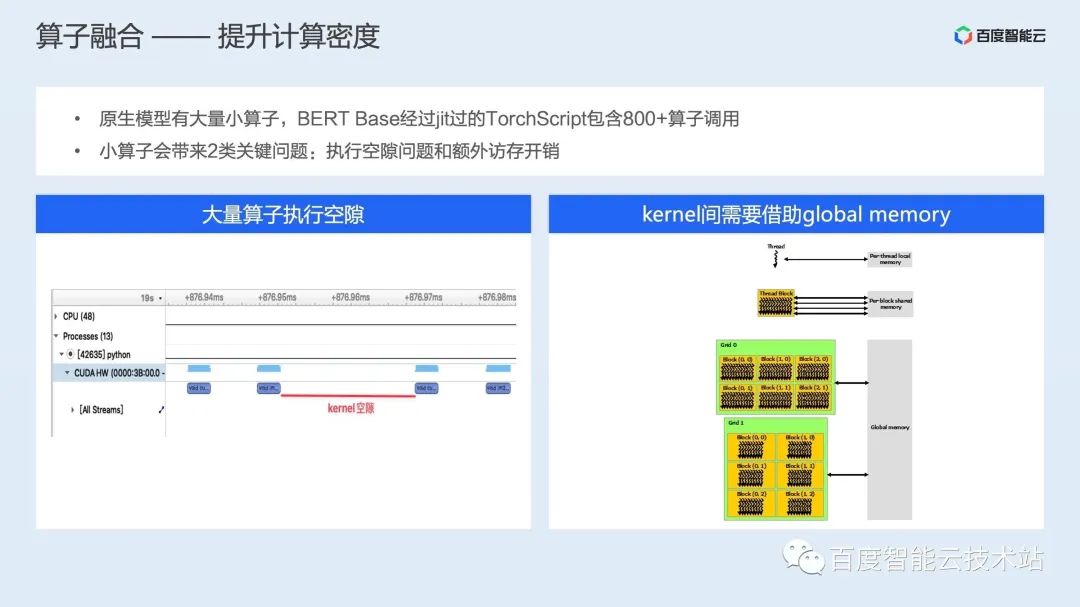
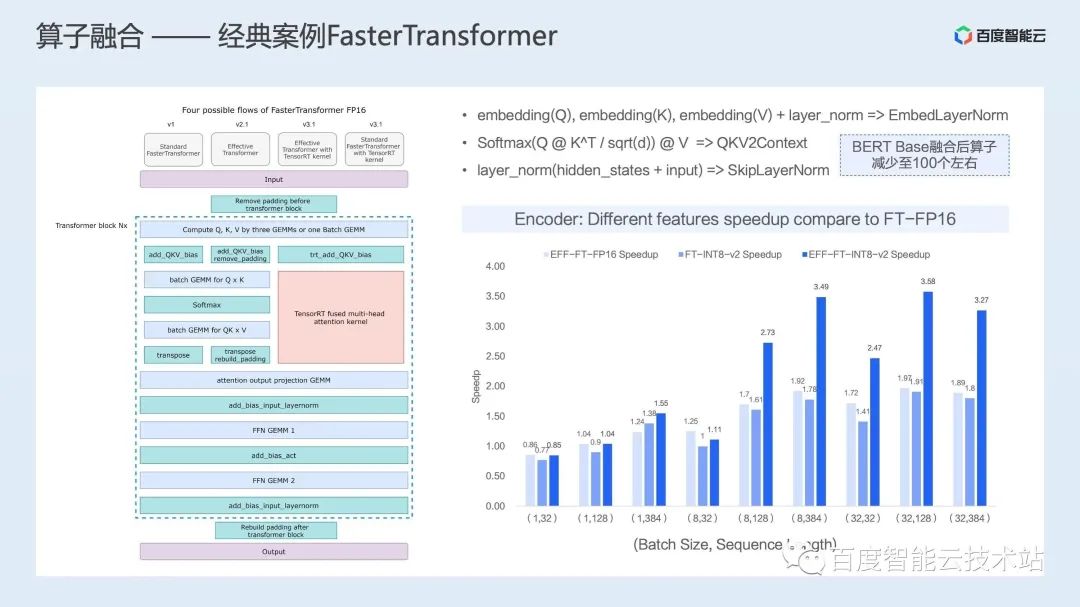
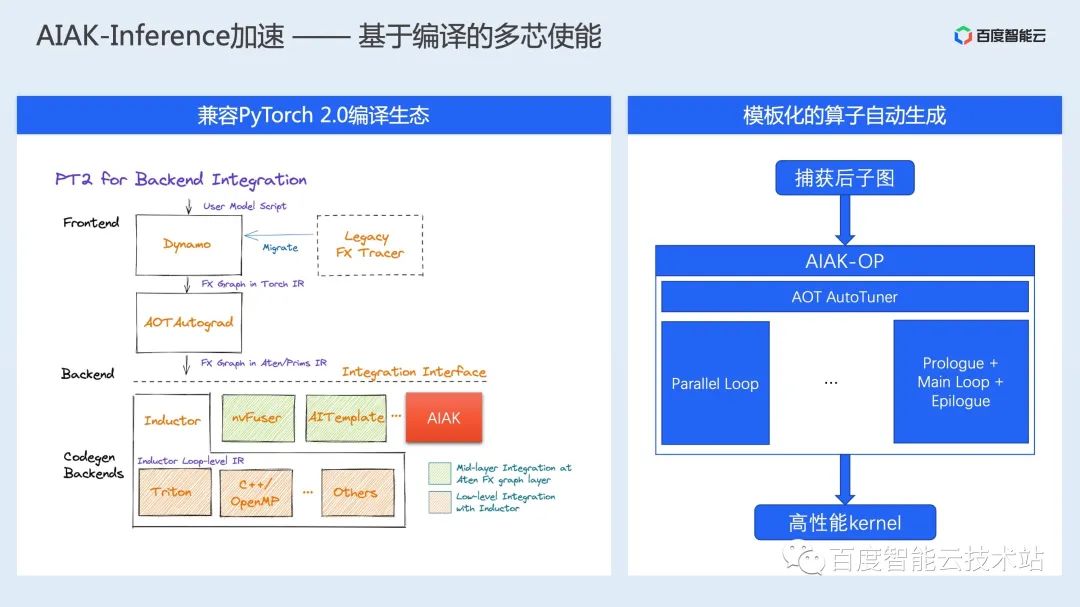
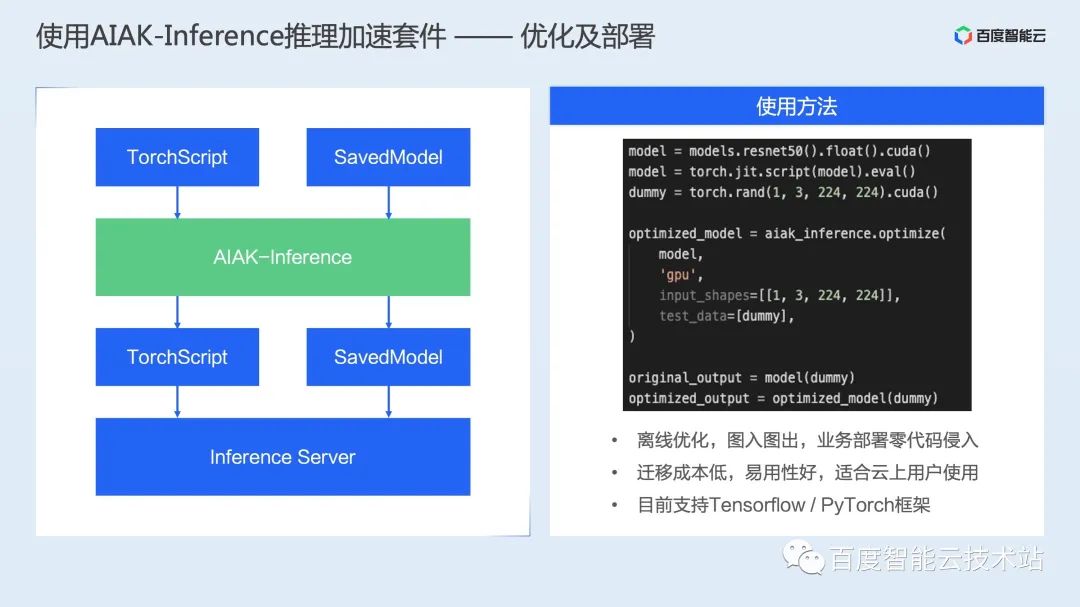
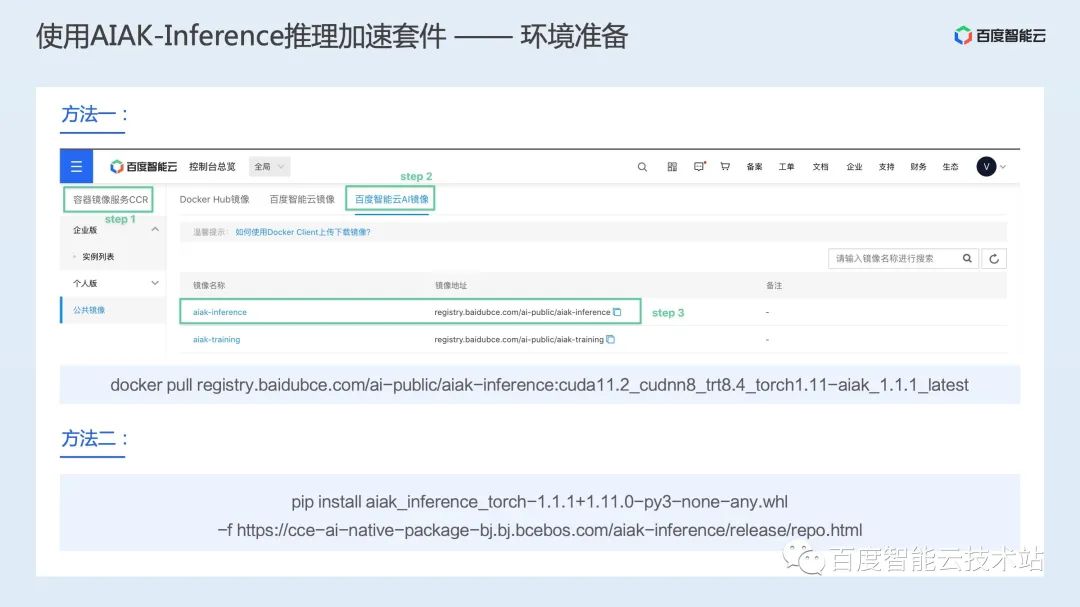
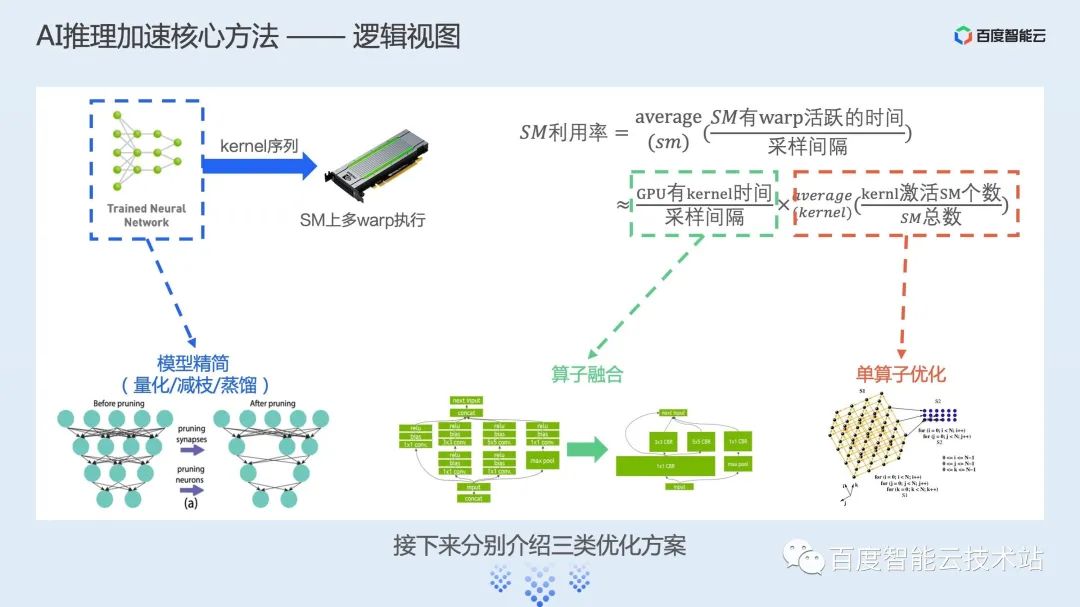
图接入:解决多框架动态图/静态图捕获问题,将动态图转换为推理友好的静态图; 后端抽象:支持将业界多种优化方案统一整合,通过计时的方式选择最优的加速后端; 具体加速后端,支持业界多种开源加速后端,包括飞桨提供的 FastDeploy 等;此外还有一套自研加速后端,通过图优化、图转换和加速运行时三部分对模型进行整体的推理加速; 算子库:除了使能业界最优的常见计算算子库,还针对具体场景的重点计算模式进行定制化开发,提供场景加速的算子库。

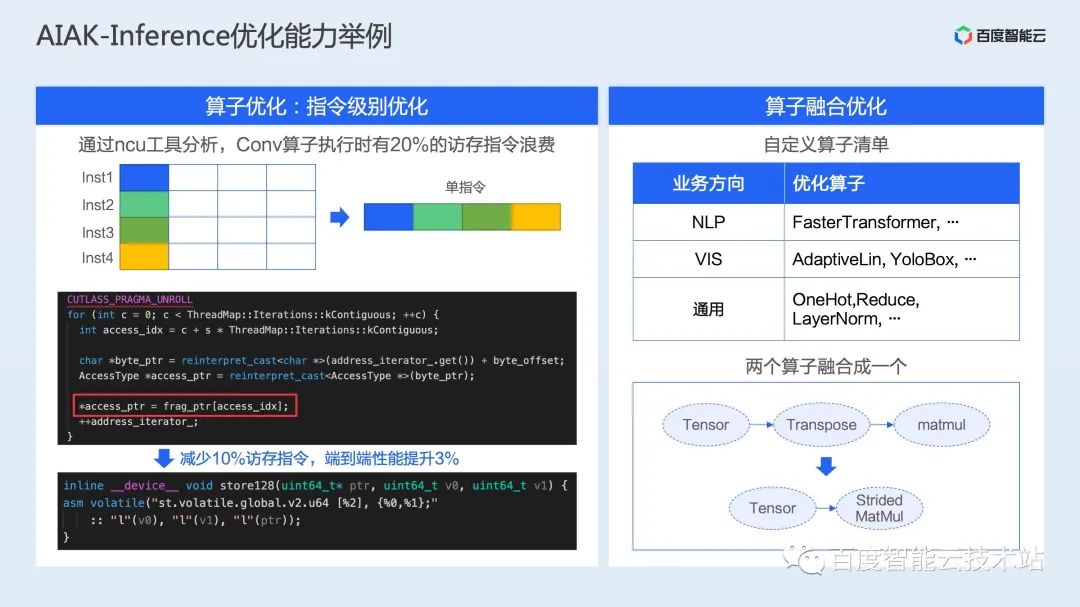
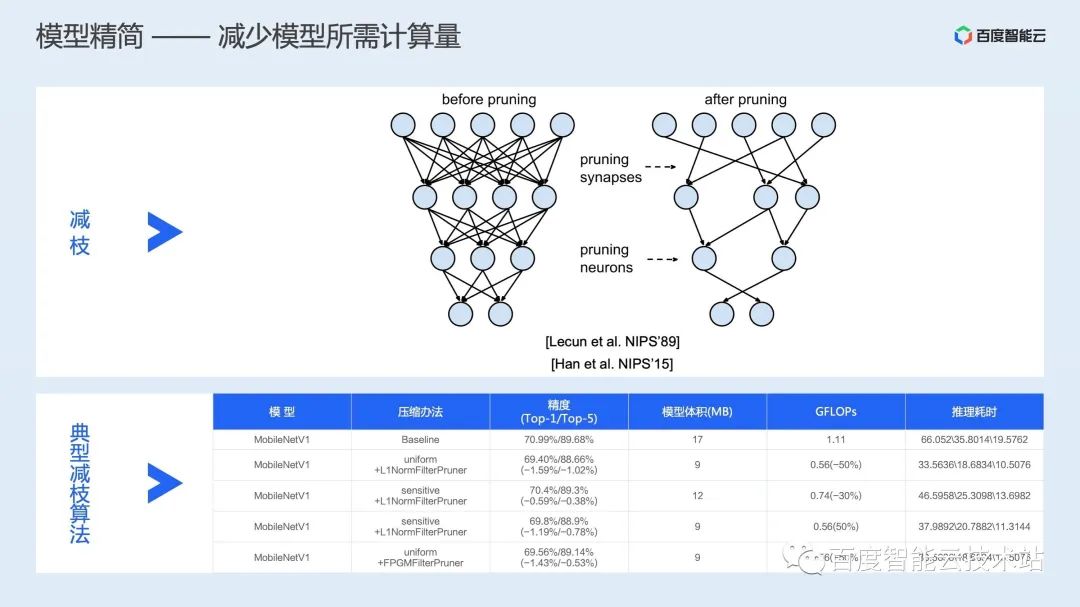
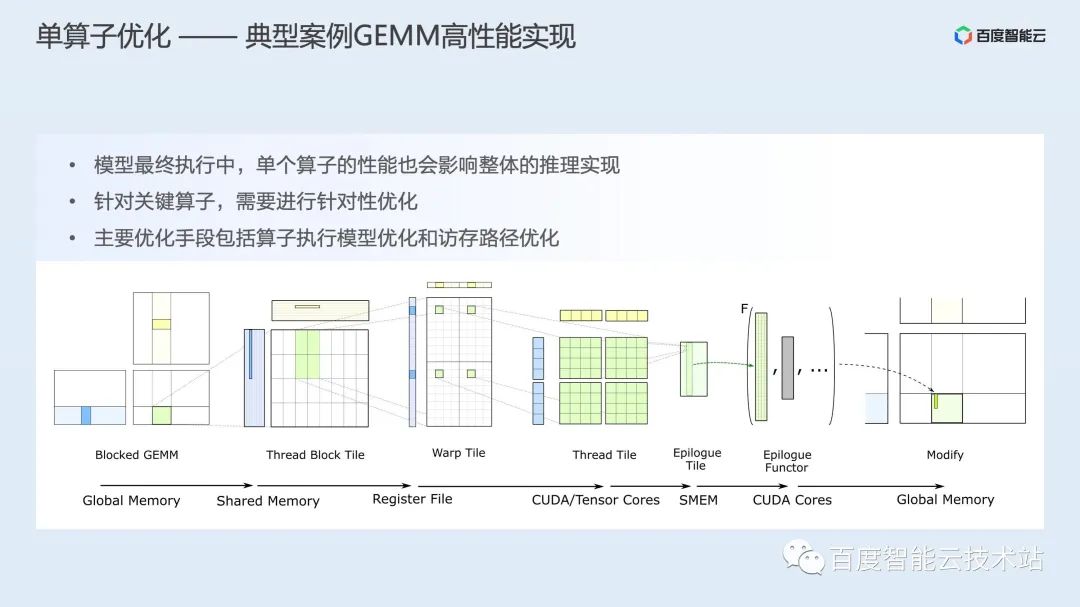
在图精简上,AIAK-Inference 除了兼容社区常见的量化、减枝、蒸馏、NAS 等方案,还提供一些数学等价代换、死代码移除等精度无算的图精简操作; 在算子融合上,AIAK-Inference 支持访存密集型算子融合、GEMM/Conv 长尾运算融合和背靠背 GEMM 融合等多种融合策略; 而针对具体的单个算子,AIAK-Inference 则通过调度、访存、模板化优化等思路,实现了一系列高性能场景化算子。